
"Парсинг сайтов" или "парсинг контента" — это процесс извлечения данных любого сайта в сети Интернет.
Типичным примером парсинга контента является копирование списка контактов из некоего веб-каталога. Однако извлечение и сохранение данных с веб-страницы в таблицу Excel работает только с небольшими объемами данных и занимает значительное время. Чтобы обработать крупные массивы данных, нужна автоматизация. И здесь в дело вступают веб-парсеры.
Парсинг сайтов осуществляется при помощи специальной программы "веб-парсера" или "бота" или "веб-паука" (обычно все эти понятия используются как синонимы). Веб-парсер сканирует веб-страницы, загружает контент, извлекает из него нужные данные и затем сохраняет их в файлах или базе данных.
Для чего используется парсинг сайтов
Парсинг сайтов может использоваться для автоматизации всевозможных задач по сбору данных. Веб-парсеры вместе с другими программами могут делать практически все то же самое, что делает человек в браузере и многое другое. Они могут автоматически заказать вашу любимую еду, купить билеты на концерт, как только они станут доступны, периодически сканировать сайты электронной коммерции и отправлять вам текстовые сообщения, когда цена на интересующий вас товар снизится, и т. д.
Как работает веб-парсер
Веб-парсер — это программа или скрипт, который используется для загрузки контента веб-страниц (обычно текста отформатированного на HTML) и извлечения из него данных.
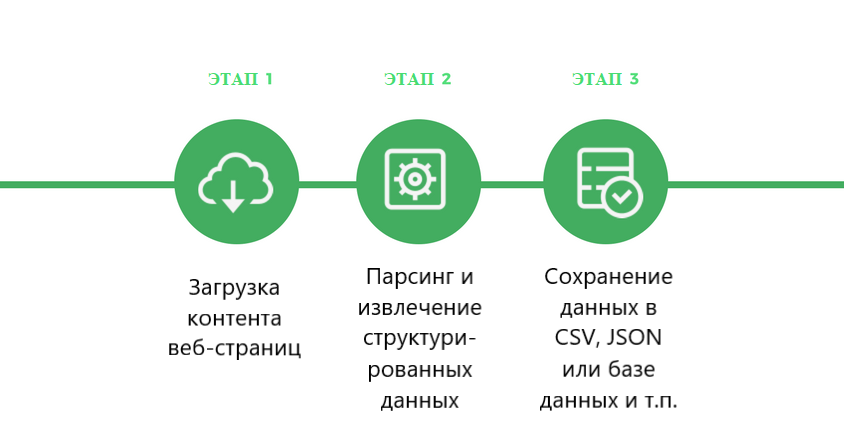
В действительности веб-парсеры имеют несколько более сложную структуру, чем показанная на диаграмме. Они состоят из множества модулей, которые выполняют различные функции.
Какие компоненты могут быть в веб-парсере
Веб-парсер сканирует веб-сайты, извлекает из ни данные, преобразует их в удобный структурированный формат и сохраняет в файле или базе данных для последующего использования.
1. "Сфокусированный" модуль веб-сканирования
Модуль веб-сканера перемещается по целевому веб-сайту, отправляя HTTP или HTTPS запросы на URL-адреса, следуя определенному шаблону или некоторой логике разбиения на страницы. Сканер загружает объекты ответа в виде содержимого HTML и передает эти данные в экстрактор. Например, сканер запустится на странице с адресом https://example.com и просканирует сайт, переходя по ссылкам на главной странице.
2. Модуль извлечения (экстрактор) или анализатор
Полученный HTML обрабатывается с использованием синтаксического анализатора, который извлекает необходимые данные из HTML в полуструктурированную форму. Существуют разные методы разбора:
- Регулярные выражения — набор регулярных выражений (RegExes) может использоваться для поиска по шаблону во время обработки текста в HTML данных. Этот метод полезен решения для простых задач, вроде извлечения списка всех электронных адресов на веб-странице. Но не подходит для решения более сложных задач, таких как получение различных полей на странице с описанием товара на сайте электронной коммерции. Тем не менее, регулярные выражения бывают крайне полезны при последующих преобразовании и очистке данных.
- Анализ HTML — это наиболее часто используемый метод анализа данных с веб-страницы. Большинство веб-сайтов опираются на некую базу данных, из которой они читают контент и создают разные страницы по одинаковым шаблонам. HTML анализаторы преобразуют код HTML в древовидную структуру, по которой можно перемещаться программно с использованием полуструктурированных языков запросов, таких как XPath или CSS-селекторы.
- Анализ DOM с использованием полных или "безголовых" (без визуального интерфейса) браузеров — Поскольку Интернет превратился в сложные веб-приложения, которые сильно зависят от JavaScript, простой загрузки веб-страницы и кода HTML стало недостаточно. Такие страницы динамически обновляют данные внутри браузера, не отправляя вас на другую страницу (используя запросы AJAX). Загружая HTML код таких веб-страниц, вы получаете только внешнюю HTML оболочку веб-приложения. Она будет содержать только относительные ссылки и не слишком релевантный контент или данные. Для таких веб-сайтов проще использовать полноценный браузер, такой как Firefox или Chrome. Этими браузерами можно управлять с помощью инструмента автоматизации браузера, такого как Selenium (пример см. на сайте http://lsreg.ru/parsing-sajtov-na-c/) или Puppeteer. Данные, получаемые этими браузерами, могут затем запрашиваться с помощью селекторов DOM, таких, например, как XPath.
- Автоматическое извлечение с использованием искусственного интеллекта — эта продвинутая техника более сложна и в основном используется, когда сканируется несколько сайтов, подпадающих под определенную вертикаль. Вы можете обучать веб-парсеры, используя модели машинного обучения по извлечению данных. Например, можно использовать модели распознавания именованных объектов для получения данных, таких как контактные данные, с просканированных веб-страниц.
3. Модуль преобразования и очистки данных
Данные, извлеченные синтаксическим анализатором, не всегда имеют формат, подходящий для немедленного использования. Большинство извлеченных наборов данных нуждаются в той или иной форме "очистки" или "преобразования". Для выполнения этой задачи используются регулярные выражения, операции со строками и методы поиска.
Если веб-парсер извлекает данные с небольшого количества страниц, то обычно извлечение и преобразование выполняются в одном модуле.
4. Модуль сериализации и сохранения данных
После получения очищенных данных их необходимо сериализировать в соответствии с заданными моделями данных. Это последний модуль, который выводит данные в стандартном формате, который может храниться в базах данных (Oracle, SQL Server, MongoDB и т.д.), в файлах JSON/CSV или передаваться в хранилища данных.
Как написать веб-парсер
Есть много способов написать веб-парсер. Вы можете написать код с нуля для всех вышеперечисленных модулей или использовать интегрированные среды с абстрактными слоями этих модулей. Написание кода с нуля отлично подходит для решения небольших задач по парсингу данных. Но как только парсинг выходит за рамки нескольких разных типов веб-страниц, лучше воспользоваться фреймворком.
Кроме этого, существуют инструменты для парсинга веб-страниц с помощью визуального интерфейса, где вы можете задавать необходимые для извлечения данные, и сервис автоматически создаст веб-парсер с этими инструкциями. Однако, подобные веб-инструменты находятся еще в сыром состоянии. Для более менее сложных задач вам все же придется написать код веб-парсинга самостоятельно.